O marca de classe, Também conhecido como ponto médio, é o valor que está no centro de uma classe, que representa todos os valores que estão nessa categoria. Fundamentalmente, a marca da classe é usada para calcular certos parâmetros, como a média aritmética ou o desvio padrão..
Portanto, a marca da classe é o ponto médio de qualquer intervalo. Este valor também é muito útil para encontrar a variância de um conjunto de dados já agrupados em classes, o que por sua vez nos permite entender a que distância do centro esses dados específicos estão localizados.

Índice do artigo
Para entender o que é uma marca de classe, o conceito de distribuição de frequência é necessário. Dado um conjunto de dados, uma distribuição de frequência é uma tabela que divide os dados em várias categorias chamadas classes..
A referida tabela mostra a quantidade de elementos que pertence a cada classe; o último é conhecido como frequência.
Nesta tabela, parte da informação que obtemos dos dados é sacrificada, pois em vez de termos o valor individual de cada elemento, só sabemos que pertence a essa classe.
Por outro lado, ganhamos uma melhor compreensão do conjunto de dados, pois desta forma é mais fácil apreciar os padrões estabelecidos, o que facilita a manipulação dos referidos dados..
Para fazer uma distribuição de frequência, devemos primeiro determinar o número de classes que queremos fazer e escolher seus limites de classe..
Escolher quantas classes levar deve ser conveniente, levando em consideração que um pequeno número de classes pode ocultar informações sobre os dados que queremos estudar e um muito grande pode gerar muitos detalhes que não são necessariamente úteis.
Os fatores que devemos levar em conta na hora de escolher quantas aulas atender são vários, mas entre estes dois se destacam: o primeiro é levar em conta quantos dados temos que considerar; a segunda é saber quão grande é o intervalo da distribuição (ou seja, a diferença entre a maior e a menor observação).
Depois de ter as classes já definidas, passamos a contar quantos dados existem em cada classe. Este número é chamado de frequência das classes e é denotado por fi.
Como já dissemos, temos que uma distribuição de frequência perde a informação que vem individualmente de cada dado ou observação. Por isso, busca-se um valor que represente toda a classe a que pertence; este valor é a marca da classe.
A marca da classe é o valor central que uma classe representa. É obtido somando os limites do intervalo e dividindo esse valor por dois. Podemos expressar isso matematicamente da seguinte maneira:
xeu= (Limite inferior + limite superior) / 2.
Nesta expressão xeu denota a marca da i-ésima classe.
Dado o seguinte conjunto de dados, forneça uma distribuição de frequência representativa e obtenha a marca das classes correspondentes.

Como os dados com o maior valor numérico são 391 e o menor é 221, temos que o intervalo é 391 -221 = 170.
Vamos escolher 5 turmas, todas do mesmo tamanho. Uma maneira de escolher as classes é a seguinte:

Observe que cada dado está em uma classe, eles são separados e têm o mesmo valor. Outra forma de escolher as classes é considerar os dados como parte de uma variável contínua, podendo atingir qualquer valor real. Neste caso, podemos considerar classes da forma:
205-245, 245-285, 285-325, 325-365, 365-405
No entanto, essa forma de agrupar dados pode apresentar algumas ambigüidades limítrofes. Por exemplo, no caso de 245, surge a questão: a que classe pertence, a primeira ou a segunda?
Para evitar essa confusão, uma convenção de terminal é feita. Desta forma, a primeira aula será o intervalo (205.245], a segunda (245.285], e assim por diante.

Uma vez definidas as classes, procedemos ao cálculo da frequência e temos a seguinte tabela:
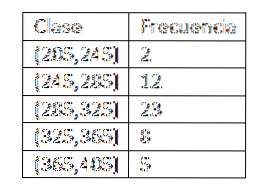
Depois de obter a distribuição de frequência dos dados, procedemos para encontrar as marcas de classe de cada intervalo. Com efeito, temos que:
x1= (205+ 245) / 2 = 225
xdois= (245+ 285) / 2 = 265
x3= (285+ 325) / 2 = 305
x4= (325+ 365) / 2 = 345
x5= (365+ 405) / 2 = 385
Podemos representar isso pelo seguinte gráfico:
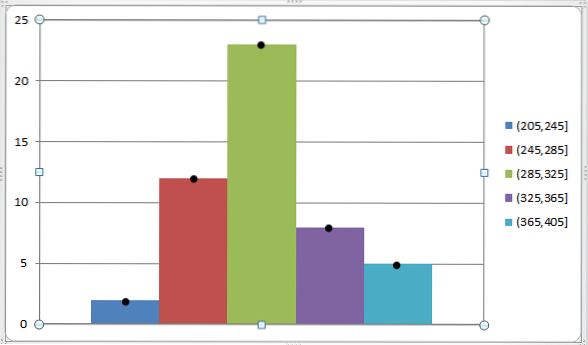
Conforme mencionado anteriormente, a marca da classe é muito funcional para encontrar a média aritmética e a variância de um grupo de dados que já foram agrupados em diferentes classes..
Podemos definir a média aritmética como a soma das observações obtidas entre o tamanho da amostra. Do ponto de vista físico, sua interpretação é como o ponto de equilíbrio de um conjunto de dados.
Identificar um conjunto de dados inteiro por um único número pode ser arriscado, portanto, a diferença entre esse ponto de equilíbrio e os dados reais também deve ser levada em consideração. Esses valores são conhecidos como desvio da média aritmética, e com eles buscamos determinar o quanto varia a média aritmética dos dados..
A forma mais comum de encontrar este valor é pela variância, que é a média dos quadrados dos desvios da média aritmética.
Para calcular a média aritmética e a variância de um conjunto de dados agrupados em uma classe, usamos as seguintes fórmulas, respectivamente:
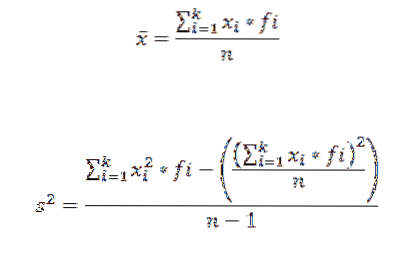
Nessas expressões xeu é a i-ésima marca da classe, feu representa a frequência correspondente ek o número de classes nas quais os dados foram agrupados.
Fazendo uso dos dados fornecidos no exemplo anterior, temos que expandir um pouco mais os dados da tabela de distribuição de frequência. Você obtém o seguinte:
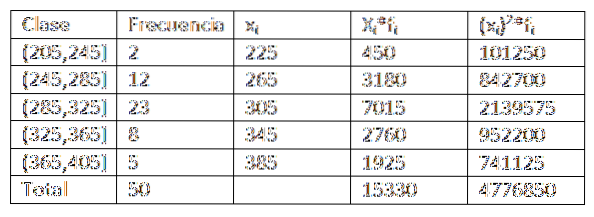
Então, ao substituir os dados na fórmula, ficamos que a média aritmética é:
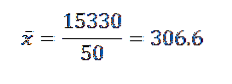
Sua variância e desvio padrão são:
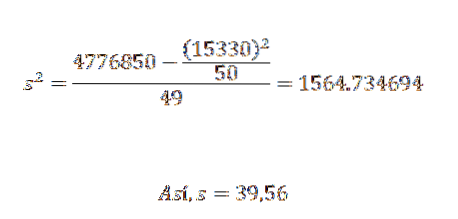
A partir disso, podemos concluir que os dados originais têm uma média aritmética de 306,6 e um desvio padrão de 39,56..


Ainda sem comentários